A while ago we kept running into a strange failure while using multiple coding agents in the same repo.
Not crashes.
Not broken syntax.
Not some obvious “the model got confused” moment.
The nastier version.
Two agents touch the same shared file. Both make perfectly reasonable changes. One write lands after the other. The build still passes. The repo still looks clean.
But part of the work is gone.
That was the moment Klock began.
At first it looked like bad luck. Then it happened again. Then again. Same pattern every time: from the outside, the run looked successful. Underneath, correctness was already broken.
That was the bug we built Klock around.

What made this feel serious was not the theory. It was the fact that we could reproduce it.
We ran a real concurrent editing setup and watched intended changes disappear while the build still passed. In our benchmark, concurrent agents silently lost roughly 24% of intended changes. In some cases, important functionality effectively vanished without any obvious error signal. No dramatic explosion. No clean stack trace. Just missing work.
That was the moment this stopped feeling like “agent weirdness” and started feeling like a systems problem.
Because that is what it is.
A lot of multi-agent failures do not look like AI failures. They look like old systems failures wearing new clothes: read-modify-write races, bad handoffs, shared-state contamination, timing bugs, silent overwrites.
The uncomfortable truth
Once multiple agents share mutable resources, you do not just have an AI workflow anymore. You have a coordination problem.
And coordination problems do not disappear because the interface looks futuristic.
That realization changed how we thought about the whole thing. We did not want to build another vague “agent platform.” We did not want to hand-wave the failure away with better prompting, nicer orchestration, or a cleaner demo.
We wanted to solve the actual bug.
The one-sentence version of Klock
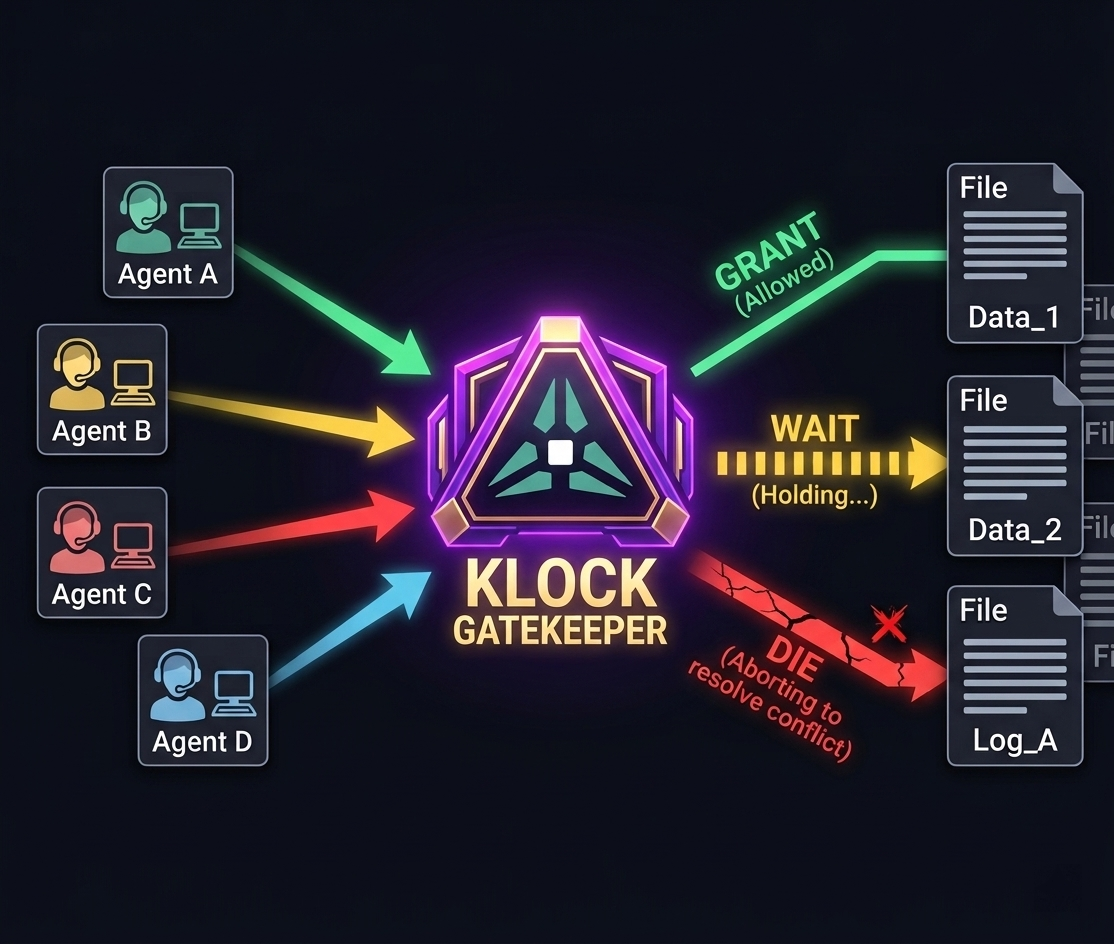
Klock is a local coordination layer for AI coding agents working in the same repo.
Before an agent mutates a shared file, it asks Klock first.
Klock returns one of three scheduling decisions: GRANT, WAIT, or DIE.
That is the whole shift.
Instead of discovering later that one agent silently overwrote another, the conflict becomes explicit before it hits disk.
GRANT means the agent can proceed.
WAIT means the agent has to hold.
DIE means the agent should abort and resolve the conflict instead of pretending the write is safe.
That is what Klock does. It sits before mutation, not after.

One thing we learned very quickly is that people do not really understand this problem from a slogan.
They understand it when they watch two agents touch the same file and one silently erase part of the other.
That is why the tiny repro ended up mattering more than the pitch.
You run the unprotected version and watch the lost update happen. Then you run the protected version and see the scheduling decision happen before the write. Same setup. Same agents. Different outcome.
That was the first time Klock felt like a real product instead of a research-heavy repo with good internals.
And that is also why the open-source release is deliberately narrow.
OSS v1 is deliberately narrow
OSS v1 is not trying to be everything. It is not trying to be a full agent platform, a giant workflow suite, a universal enforcement layer, or a broad “works with everything automatically” claim.
It is smaller than that on purpose.
The wedge is simple:
multiple coding agents
same repo
shared files
silent conflicting edits
explicit coordination before mutation
That is the bug.
That is the product.
The open-source release focuses on exactly that:
klock-core as the Rust coordination engine
klock-py and klock-js as the SDK entry points
klock-langchain as the first polished integration path
klock-cli as the local coordination server
a proof set that shows without Klock, with Klock, and visible GRANT / WAIT / DIE behavior
Nothing inflated. Nothing hidden behind a giant promise. Just something you can actually install, run, inspect, and argue with.
That mattered a lot to me.
A lot of technical projects die in the gap between “the internals are good” and “a stranger can actually try this in five minutes.”
That gap is what we wanted to close.
For OSS v1, we made LangChain the first polished integration path because one real path beats ten vague compatibility claims.
Not because LangChain is the entire story. Because one real integration is more valuable than ten vague compatibility claims.
If the local workflow is annoying, nobody gets far enough to care about your architecture. So we worked hard to make the narrow path feel real: local server, explicit coordination, clear outcomes, visible proof.
That is also why we open-sourced it now.
Not because we think we have finished the category. Not because the enterprise story is done. Not because everything around it is complete.
We open-sourced it because this bug is real, reproducible, and easy to underestimate. And the best way to make that obvious was to ship something concrete enough that people could see it for themselves.
If you want to understand Klock in under a minute, do not start with the architecture. Start with the tiny repro.
That is still the best entry point.
Run the unprotected version.
Watch the lost update happen.
Run the protected version.
Watch the conflict become explicit before the write.
Then, if you want the more realistic path, move to the LangChain integration.
That is the shape of OSS v1:
tiny repro first
real integration second
everything else after
The repo is on GitHub under waythor-lab/klock-core. The docs and site are on klockcore.com.
The important part, though, is not the repo link. It is the bug.
The dangerous failures are not always the loud ones.
That is the class of failure we wanted to drag into the light.
That is why we built Klock.
And that is why we open-sourced it.
Try it yourself
Start with the smallest proof, then move to the full workflow
The fastest way to understand Klock is still to watch the failure happen first, then watch coordination make the conflict explicit before the write lands.